If you watch a human pentester start an engagement, the first day usually doesn't involve any attacks. It involves a notebook, or a whiteboard, or a text file, and a lot of clicking around. They're mapping the target. What resources does this application have? Folders, reports, files, users, comments. What's the noun-list? For each one, what actions does the app support? Can you create them, list them, edit them, delete them, export them? What fields do those actions take? Where are the trust boundaries? What does an authenticated user see that an unauthenticated one doesn't? What does a regular user see that an admin doesn't?
Reconnaissance
This step has a name in the pentesting world (reconnaissance, or "recon"), but the inside word for what's actually happening is understanding the application as a system. By the end of day one, the tester has a picture in their head (or on the whiteboard) of what the app is. Only then do they start poking at it.
There's a reason for the order. You can't meaningfully attack what you don't understand. A pentester who skips the mapping step and goes straight to firing payloads at URLs will find some things (the things that match well-known patterns) and miss most of what matters. The interesting bugs are almost never in the URL itself. They're in the relationship between resources, the gaps between actions, the fields that shouldn't be writable but are.
What most automated tools do instead
Most automated security tools skip this step entirely.
They have a list of URLs (sometimes discovered, sometimes provided), a list of payloads, and they iterate. SQL injection payload against parameter, XSS payload against parameter, command injection payload against parameter. Move on to the next URL. The model of the application is implicit at best. A flat bag of endpoints with no sense of which ones belong together or what they collectively do.
This is partly historical. Tools like Burp and Nessus were built in an era when the web was simpler and most apps were closer to a directory of pages than a coherent application. It's partly economic, because building a real model of the target is expensive and most scanners optimize for breadth over depth. And it's partly methodological. The people who build automated tools mostly come from the tooling side, not the pentesting side, and the gap between "how scanners work" and "how testers work" has been allowed to widen for a long time.
The result is that most automated security tools produce depth-one coverage. They find what matches templates and miss the systemic stuff. A scanner can find a SQL injection because the symptom is local: payload in, error out. It struggles with broken object-level authorization, because the symptom is not local. You only know one user is accessing another user's data by understanding that there are users, with resources that belong to specific users, with actions that should be scoped.
The same gap shows up in mass assignment, business logic flaws, privilege escalation, indirect object references. Most of the OWASP Top 10 categories that actually matter for a small SaaS company being asked about security by their enterprise customer. They all require understanding the app as a system, not as a list of URLs.
When AI agents arrived in this space, most of them inherited the same shape. Faster scanners with smarter payload selection. Same depth-one coverage problem.
The surface graph
A few weeks into building the tool, this gap became impossible to ignore. The agents kept failing in the same way. They could attack endpoints individually but they couldn't reason about the application as a system. Tests that needed to know "this resource has an update action and the body takes these fields" required the agent to guess the right shape, and guessing was unreliable.
So I added a step. Before any agent touches the target, the tool now runs a recon pass that builds a structured model of the application. A list of resources, with the actions each one supports, the fields those actions take, and observed examples of each.
It looks like this:
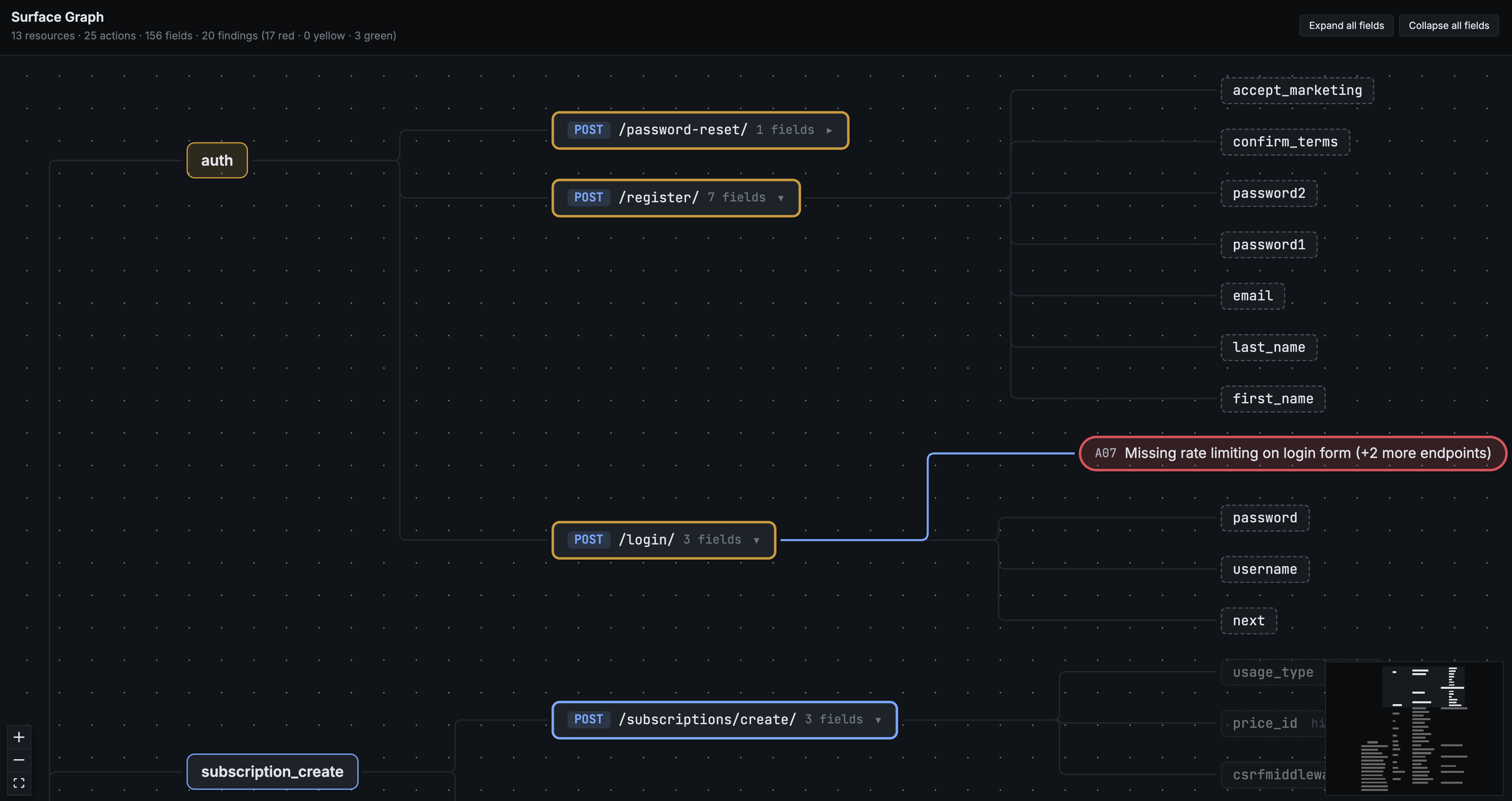
Thirteen resources. Twenty-five actions across them. A hundred and fifty-six fields. Twenty findings color-coded against the surface. The auth resource cluster shows a password-reset action, a register action with seven fields, and a login action.
The graph isn't a marketing visualization. It's the same model the agents work from internally. When the agents test BOLA on folders, they look up the folder resource's update action, find the URL template and the field shape, and run a structured test instead of asking the model to construct one. When the IDOR primitive enumerates IDs, it uses the recon-observed sample IDs from the model. So a resource with sparse IDs like 14, 89, 312, 5871 actually gets tested, instead of walking a synthetic ±10 ladder that would never reach the real IDs.
Most of the recent improvements to the tool followed from this one addition. Once the agents had a real picture of the application, the failure modes that came from guessing went away.
Why this matters for the deliverable
The other thing the model unlocked is the report.
A traditional pentest report tells the customer what's broken. That's useful but incomplete. What the customer's enterprise auditor actually wants to know is what was tested. What surface area was covered, what categories were checked, what came back clean. A report that only lists findings can't answer that question.
The customer's report now includes a "Resources tested" section that mirrors the surface graph. Every resource the recon found, every action tested against it, every finding (or absence of findings) attached to it. The customer can hand this to their auditor and answer the real question (what did you test, and what held?), not just what did you find?
That ends up being the thing the buyer actually wants to send to their enterprise customer's security team. Findings are scary. A structured picture of what was tested is reassurance.
The broader observation
This isn't really about a domain model or a surface graph or a particular technical decision. It's about a methodological choice that runs underneath every automated security tool. Do you treat the application as a list of URLs, or as a system of resources?
Almost every existing tool, including most of the new AI-driven ones, treats it as a list of URLs. They scale up by adding more payloads and faster agents. The model of the target stays implicit.
The bet I'm making is that small dev teams need the second kind. Not because more sophistication is always better, but because the bugs that show up in real enterprise security questionnaires are systemic bugs, not URL-shaped ones. BOLA, mass assignment, broken access control, indirect object references. All of them require understanding the app as a coherent system.
That's what a human pentester would do on day one. There's no good reason an AI-driven tool shouldn't.
About the author


Join my mailing list
Stay up to date with everything Skripted.
Sign up for periodic updates on #IaC techniques, interesting AWS services and serverless.